As informações apresentadas nesta página são complementares às diretrizes de desenvolvimento de software do Ministério da Saúde.
A arquitetura das aplicações Java está em constante atualização por parte equipe da COATIC. As versões mencionadas nessa página estão sujeitas à alteração.
¶ Introdução
- As diretrizes aqui contidas não são exaustivas. Casos omissos devem ser analisados pela COATIC.
- Para novos projetos, a COATIC poderá disponibilizar a estrutura inicial da aplicação.
¶ Versão Java
Devido a recentes mudanças nos termos de serviço da Oracle JVM, dê preferência sempre a versão Open Source da JDK (tais como Amazon Corretto ou OpenJDK).
¶ Arquitetura
¶ Introdução
Este documento descreve a arquitetura modular de aplicações backend em Java, contemplando dois frameworks principais suportados pelo DATASUS: Spring Boot e Quarkus. Ambos são frameworks para desenvolvimento de aplicações web e microsserviços. A arquitetura modular permite que a aplicação seja escalável e facilmente mantida, dividindo a funcionalidade em módulos independentes.
- Spring Boot: framework consolidado no ecossistema Java, com vasto suporte a bibliotecas e integrações. Recomendado para projetos legados, equipes já familiarizadas com o ecossistema Spring e cenários que demandam bibliotecas Spring maduras (Batch, Integration, etc.).
- Quarkus: framework cloud-native otimizado para Kubernetes e GraalVM, com suporte a compilação nativa. Recomendado para novos microsserviços, ambientes serverless, containers com restrição de memória e cenários que exigem inicialização sub-segundo.
A escolha do framework deve ser feita em conjunto com a COATIC no início do projeto.
¶ Visão geral
As arquiteturas de referência podem existir ou serem usadas em diferentes níveis de abstração e a partir de diversos pontos de vista. Esses pontos de vista ou aspectos, são demonstrados através de um padrão conhecido como “Visões 4+1”. Desse modo, o arquiteto de software pode selecionar a visão que seja mais adequada, por exemplo: apenas um design de arquitetura ou um design e uma implementação, em variados graus de conclusão.
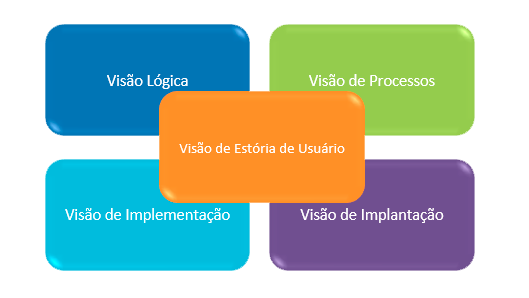
A arquitetura é composta por quatro camadas: infraestrutura, serviço, API e aplicação. A camada de infraestrutura fornece recursos compartilhados, como autenticação, autorização, segurança e gerenciamento de sessões. A camada de serviço fornece serviços de negócios, como gerenciamento de usuários, gerenciamento de pedidos, gerenciamento de estoque e gerenciamento de pagamentos.
A camada de API fornece as interfaces de programação de aplicativos (APIs) que são usadas por outras aplicações para acessar os serviços fornecidos pela camada de serviço. A camada de aplicação contém a lógica de negócios específica da aplicação, como gerenciamento de produtos, gerenciamento de clientes e gerenciamento de faturas.
A arquitetura modular é altamente escalável, permitindo que os módulos individuais sejam escalados independentemente uns dos outros. A arquitetura também é altamente flexível, permitindo a integração de diferentes tecnologias e componentes na aplicação.
A arquitetura modular para backend em Java tem como objetivo aumentar a produtividade do desenvolvedor, fornecendo um conjunto de recursos prontos para uso. No Spring Boot isso se traduz em inicialização rápida, autoconfiguração e starter POMs. No Quarkus, em Dev Mode com hot reload, Dev Services automáticos e extensões otimizadas para runtime. Ambos são facilmente mantidos e evoluídos ao longo do tempo.
¶ Arquitetura Modular
A arquitetura modular da aplicação backend em Java Spring Boot consiste em módulos independentes que se comunicam através de interfaces claras e bem definidas. Cada módulo é responsável por uma parte específica da funcionalidade da aplicação. A arquitetura é composta pelas seguintes camadas e módulos representados pelo diagrama abaixo:

¶ Camada de Segurança
A camada de infraestrutura fornece recursos compartilhados que são usados por todos os módulos da aplicação. Esta camada consiste em módulos que fornecem recursos como autenticação, autorização, segurança, gerenciamento de sessões, gerenciamento de configurações e gerenciamento de log. Esses módulos são independentes e podem ser usados por qualquer módulo da aplicação que precise desses recursos.
¶ Camada de Serviço
A camada de serviço fornece serviços de negócios que são usados por todos os módulos da aplicação. Esta camada consiste em módulos que fornecem serviços como gerenciamento de usuários, gerenciamento de pedidos, gerenciamento de estoque e gerenciamento de pagamentos. Esses módulos são independentes e podem ser usados por qualquer módulo da aplicação que precise desses serviços.
¶ Camada de API
A camada de API fornece as interfaces de programação de aplicativos (APIs) que são usadas por outras aplicações para acessar os serviços fornecidos pela camada de serviço. Esta camada consiste em módulos que fornecem as APIs RESTful para cada serviço da camada de serviço. Cada módulo da camada de API é responsável por fornecer uma interface clara e bem definida para o serviço correspondente da camada de serviço.
¶ Camada de Aplicação
A camada de aplicação contém a lógica de negócios específica da aplicação. Esta camada consiste em módulos que fornecem a funcionalidade específica da aplicação, como gerenciamento de produtos, gerenciamento de clientes e gerenciamento de faturas. Cada módulo da camada de aplicação é responsável por implementar a lógica de negócios para a funcionalidade correspondente.
¶ Vantagens
¶ Facilidade de desenvolvimento
O Spring Boot simplifica o desenvolvimento de aplicações, permitindo que os desenvolvedores se concentrem na lógica de negócios em vez de se preocuparem com a configuração do ambiente. O Spring Boot fornece um ambiente de execução embutido que permite aos desenvolvedores executar e testar suas aplicações sem a necessidade de um servidor de aplicação separado.
¶ Modularidade
O Spring Boot permite que as aplicações sejam construídas em módulos independentes e modulares, o que facilita a manutenção e evolução da aplicação ao longo do tempo. Isso também facilita a escalabilidade da aplicação, permitindo que os módulos individuais sejam escalados independentemente uns dos outros.
¶ Flexibilidade
O Spring Boot suporta várias tecnologias e bibliotecas, o que torna possível a integração de diferentes tecnologias e componentes na aplicação, como por exemplo o Spring Data, que fornece recursos para acesso a banco de dados, e o Spring Security, que fornece recursos de autenticação e autorização.
¶ Comunidade ativa
O Spring Boot tem uma grande comunidade ativa de desenvolvedores que contribuem para o desenvolvimento e melhoria do framework. Isso significa que a documentação, fóruns de discussão, tutoriais e recursos de treinamento estão amplamente disponíveis e sempre atualizados.
¶ Produtividade
Spring Boot tem como objetivo aumentar a produtividade do desenvolvedor, fornecendo um conjunto de recursos prontos para uso, como a inicialização rápida, que permite que o desenvolvedor crie uma aplicação em questão de minutos, a autoconfiguração, que reduz o tempo de configuração e o starter POMs, que fornecem uma configuração pré-definida de dependências para uma ampla variedade de tecnologias.
¶ Escalabilidade
O Spring Boot é altamente escalável, permitindo que as aplicações cresçam com a demanda e que novos módulos sejam adicionados sem afetar os módulos existentes. A arquitetura modular e a facilidade de integração com outras tecnologias tornam a escalabilidade do Spring Boot uma das suas principais vantagens.
¶ Estrutura de diretórios
├── src
│ ├── main
│ │ ├── java
│ │ │ └── com
│ │ │ └── example
│ │ │ ├── Application.java
│ │ │ ├── config
│ │ │ │ ├── SecurityConfig.java
│ │ │ │ └── WebConfig.java
│ │ │ ├── infrastructure
│ │ │ │ ├── LoggingModule.java
│ │ │ │ ├── SecurityModule.java
│ │ │ │ └── SessionModule.java
│ │ │ ├── service
│ │ │ │ ├── ProductService.java
│ │ │ │ ├── CustomerService.java
│ │ │ │ ├── OrderService.java
│ │ │ │ └── PaymentService.java
│ │ │ ├── api
│ │ │ │ ├── dto/
│ │ │ │ ├── mapper/
│ │ │ │ ├── ProductApi.java
│ │ │ │ ├── CustomerApi.java
│ │ │ │ ├── OrderApi.java
│ │ │ │ └── PaymentApi.java
│ │ │ ├── application
│ │ │ │ ├── ProductApplication.java
│ │ │ │ ├── CustomerApplication.java
│ │ │ │ ├── OrderApplication.java
│ │ │ │ └── PaymentApplication.java
│ │ │ └── domain
│ │ │ ├── entity
│ │ │ │ ├── Product.java
│ │ │ │ ├── Customer.java
│ │ │ │ ├── Order.java
│ │ │ │ └── Payment.java
│ │ │ ├── repository
│ │ │ │ ├── ProductRepository.java
│ │ │ │ ├── CustomerRepository.java
│ │ │ │ ├── OrderRepository.java
│ │ │ │ └── PaymentRepository.java
│ │ │ └── service
│ │ │ ├── ProductServiceImpl.java
│ │ │ ├── CustomerServiceImpl.java
│ │ │ ├── OrderServiceImpl.java
│ │ │ └── PaymentServiceImpl.java
│ │ │
│ │ └── resources
│ │ ├── application.yml
│ │ └── logback.xml
│ └── test
│ ├── java
│ └── resources
└── pom.xml
Nesse exemplo, os arquivos Java estão localizados na pasta src/main/java e os recursos como arquivos YAML, HTML, CSS e JavaScript estão localizados na pasta src/main/resources. Apesar de ser possível utilizar o Spring Boot para produzir aplicações que servem páginas HTML, é importante que essa stack deve ser utilizada para desenvolvimento backend, na qual a interface de comunicação com o mundo externo são as APIs REST.
Na pasta com.example, temos a classe Application.java, que é a classe principal da aplicação e é responsável por sua inicialização. As classes Java estão organizadas em pacotes que refletem a estrutura modular da aplicação.
A pasta config contém as classes Java responsáveis pela configuração da aplicação, como SecurityConfig.java, que define as configurações de segurança. A pasta infrastructure contém módulos que fornecem recursos compartilhados, como LoggingModule.java, para gerenciamento de log.
A pasta service contém módulos que fornecem serviços de negócios, como ProductService.java e OrderService.java. A pasta api contém módulos que fornecem as APIs RESTful para cada serviço da camada de serviço.
A pasta application contém módulos que fornecem a funcionalidade específica da aplicação, como ProductApplication.java e OrderApplication.java. A pasta domain contém os modelos de domínio e os repositórios, como Product.java e ProductRepository.java.
A pasta service contém as implementações dos serviços de negócios, como ProductServiceImpl.java e OrderServiceImpl.java.
O arquivo application.yml na pasta resources contém as configurações da aplicação. O arquivo logback.xml é um arquivo de configuração do Logback, implementação da SLF4J, esta última sendo a abastração de funcionalidades relacionadas a log mais popular da comunidade Java.
Finalmente, o arquivo pom.xml é o arquivo de configuração do Maven, que é usado para gerenciar as dependências e e controlar as etapas de build, paking and deploy da aplicação.
¶ Componentes de Referência
¶ Controller (API)
O Controller é responsável por receber as solicitações HTTP e encaminhá-las para o serviço apropriado para processamento. Os Controllers são responsáveis por lidar com a entrada do usuário e podem validar a entrada antes de encaminhá-la para o serviço. Os controllers devem expor sempre interfaces REST. Casos omissos devem ser analisados individualmente.
Suponha que estamos criando uma aplicação para gerenciar informações de alunos em uma escola. Aqui está um exemplo de Controller que recebe solicitações HTTP e retorna uma resposta JSON.
@RestController
@RequestMapping("/api/students")
public class StudentController {
@Autowired
private StudentService studentService;
@GetMapping("/{id}")
public ResponseEntity<StudentDTO> getStudentById(@PathVariable Long id) {
Student student = studentService.getStudentById(id);
if (student == null) {
return ResponseEntity.notFound().build();
}
StudentDTO studentDTO = new StudentDTO(student);
return ResponseEntity.ok().body(studentDTO);
}
@PostMapping
public ResponseEntity<StudentDTO> createStudent(@RequestBody StudentDTO studentDTO) {
Student student = studentService.createStudent(studentDTO.toStudent());
return ResponseEntity.created(URI.create("/api/students/" + student.getId())).body(new StudentDTO(student));
}
@PutMapping("/{id}")
public ResponseEntity<StudentDTO> updateStudent(@PathVariable Long id, @RequestBody StudentDTO studentDTO) {
Student student = studentService.getStudentById(id);
if (student == null) {
return ResponseEntity.notFound().build();
}
student.setName(studentDTO.getName());
student.setGrade(studentDTO.getGrade());
student = studentService.updateStudent(student);
return ResponseEntity.ok().body(new StudentDTO(student));
}
@DeleteMapping("/{id}")
public ResponseEntity<Void> deleteStudent(@PathVariable Long id) {
Student student = studentService.getStudentById(id);
if (student == null) {
return ResponseEntity.notFound().build();
}
studentService.deleteStudent(student);
return ResponseEntity.noContent().build();
}
}
Nesse exemplo, a classe StudentController é responsável por lidar com as solicitações HTTP para o recurso "alunos". O Controller possui quatro métodos para lidar com solicitações GET, POST, PUT e DELETE.
No método getStudentById, o Controller recebe um ID de aluno como parâmetro e retorna um objeto StudentDTO que contém as informações do aluno. Se o aluno não existir, o método retorna uma resposta 404.
No método createStudent, o Controller recebe um objeto StudentDTO como parâmetro e cria um novo aluno usando o método createStudent do serviço. O método retorna um objeto StudentDTO que contém as informações do novo aluno e uma resposta HTTP 201 que indica que o aluno foi criado com sucesso.
No método updateStudent, o Controller recebe um ID de aluno e um objeto StudentDTO como parâmetros e atualiza as informações do aluno usando o método updateStudent do serviço. O método retorna um objeto StudentDTO que contém as informações atualizadas do aluno.
No método deleteStudent, o Controller recebe um ID de aluno como parâmetro e exclui o aluno usando o método deleteStudent do serviço. O método retorna uma resposta HTTP 204 que indica que o aluno foi excluído com sucesso.
Nesse exemplo, a classe StudentDTO é usada para representar os dados de um aluno na resposta JSON. A classe StudentDTO contém apenas os campos que devem ser expostos na API e usa os getters e setters para acessar os dados do aluno.
public class StudentDTO {
private Long id;
private String name;
private int grade;
public StudentDTO() {
}
public StudentDTO(Student student) {
this.id = student.getId();
this.name = student.getName();
this.grade = student.getGrade();
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getGrade() {
return grade;
}
public void setGrade(int grade) {
this.grade = grade;
}
public Student toStudent() {
Student student = new Student();
student.setId(this.id);
student.setName(this.name);
student.setGrade(this.grade);
return student;
}
}
¶ Service
O Service é responsável por fornecer a lógica de negócios da aplicação. Os Services são responsáveis por processar as solicitações recebidas dos Controllers e fornecer uma resposta apropriada.
¶ Repository
O Repository é responsável pelo acesso a dados na aplicação. Os Repositories são responsáveis por recuperar, criar, atualizar e excluir dados de um banco de dados ou outro sistema de armazenamento de dados.
Suponha que estamos criando uma aplicação para gerenciar informações de alunos em uma escola. Aqui está um exemplo de um Repository que lida com operações de persistência em um banco de dados.
@Repository
public interface StudentRepository extends JpaRepository<Student, Long> {
}
Nesse exemplo, a interface StudentRepository estende a interface JpaRepository fornecida pelo Spring Data JPA. A interface JpaRepository já fornece vários métodos para lidar com operações CRUD básicas, como salvar, atualizar, excluir e consultar entidades.
Além dos métodos fornecidos pelo JpaRepository, podemos definir nossos próprios métodos personalizados na interface StudentRepository. Por exemplo, podemos definir um método que retorna uma lista de alunos com uma determinada nota:
@Repository
public interface StudentRepository extends JpaRepository<Student, Long> {
List<Student> findByGrade(int grade);
}
Nesse exemplo, o método findByGrade é definido para retornar uma lista de alunos com uma determinada nota. O método usa a convenção de nomenclatura do Spring Data JPA para definir a consulta: o prefixo findBy indica que estamos consultando um campo específico da entidade e o sufixo Grade indica o nome do campo que estamos consultando.
Em resumo, o Spring Data JPA torna muito fácil definir Repositories em Java Spring Boot. Através do uso da interface JpaRepository, podemos aproveitar métodos de CRUD básicos, além de definir nossos próprios métodos personalizados usando a convenção de nomenclatura do Spring Data JPA.
¶ Controle de transações
O controle transacional é uma funcionalidade importante fornecida pelo Java Persistence API (JPA) que ajuda a garantir a integridade dos dados em aplicações Java Spring Boot. O controle transacional é usado para agrupar várias operações de banco de dados em uma única transação, de forma que todas as operações sejam confirmadas ou revertidas em conjunto.
Em Java Spring Boot, o controle transacional é ativado por padrão para as operações JPA que são executadas dentro de um método anotado com @Transactional. Quando o método é executado, uma nova transação é iniciada automaticamente e todas as operações JPA que ocorrem dentro desse método são realizadas dentro da mesma transação.
Se uma exceção é lançada dentro do método anotado com @Transactional, a transação é revertida e todas as operações JPA dentro dessa transação também são revertidas. Se o método é concluído com sucesso, a transação é confirmada e todas as operações JPA dentro dessa transação também são confirmadas.
Além disso, o Java Spring Boot também fornece a capacidade de ajustar o escopo e a propagação da transação usando outras anotações, como @Transactional(propagation = Propagation.REQUIRES_NEW) para iniciar uma nova transação ou @Transactional(readOnly = true) para indicar que a transação é somente leitura.
O controle transacional é uma funcionalidade importante em aplicações Java Spring Boot que ajuda a garantir a integridade dos dados e evita que operações de banco de dados fiquem presas em um estado inconsistente. Ao usar a anotação @Transactional em métodos JPA, as operações de banco de dados são agrupadas em uma única transação, o que garante que todas as operações sejam confirmadas ou revertidas juntas.
Suponha que estamos criando uma aplicação para gerenciar informações de alunos em uma escola. Aqui está um exemplo de um método de serviço que é anotado com @Transactional para garantir o controle transacional:
@Service
public class StudentService {
@Autowired
private StudentRepository studentRepository;
@Transactional
public void addStudent(StudentDTO studentDTO) {
Student student = new Student(studentDTO.getName(), studentDTO.getGrade());
studentRepository.save(student);
}
// outros métodos do serviço
}
Nesse exemplo, o método addStudent adiciona um novo aluno ao banco de dados. Ele é anotado com @Transactional para garantir que a operação seja realizada dentro de uma única transação JPA.
O método usa o StudentRepository para salvar o novo aluno no banco de dados. O StudentRepository é injetado usando a anotação @Autowired.
Se ocorrer uma exceção dentro do método addStudent, a transação será revertida e o novo aluno não será salvo no banco de dados. Caso contrário, a transação será confirmada e o novo aluno será salvo no banco de dados.
Em resumo, a anotação @Transactional é usada para ativar o controle transacional em Java Spring Boot. Ao anotar um método com @Transactional, todas as operações JPA dentro do método são agrupadas em uma única transação, que é confirmada ou revertida como um todo. Isso ajuda a garantir a integridade dos dados e evita que operações de banco de dados fiquem presas em um estado inconsistente.
¶ Entity
Entidade é responsável por definir a estrutura de dados da aplicação. Os Models são usados pelos Controllers, Services e Repositories para definir como os dados são organizados e como eles são acessados.
Entidades são objetos que possuem uma identidade de negócios distinta que é separada dos valores de seus atributos. Duas entidades são diferentes mesmo se os valores de seus atributos forem os mesmos e não podem ser utilizadas intercambiavelmente.
Identificar entidades é importante porque elas correspondem a conceitos do mundo real que são centrais para o modelo de domínio do sistema.
@Entity
@Table(name = "TB_STUDENT", schema = "DBSIS")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank
private String name;
@Min(0)
@Max(10)
private int grade;
public Student() {
}
public Student(String name, int grade) {
this.name = name;
this.grade = grade;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getGrade() {
return grade;
}
public void setGrade(int grade) {
this.grade = grade;
}
}
Nesse exemplo, a classe Student é anotada com a anotação @Entity, indicando que ela é uma entidade que será mapeada para uma tabela no banco de dados. Além disso, a classe também possui a anotação @Id, indicando que o campo id é a chave primária da entidade.
Os campos da entidade Student são mapeados para colunas na tabela do banco de dados. Os campos name e grade são anotados com as anotações @NotBlank e @Min / @Max, respectivamente, indicando que eles são obrigatórios e que o valor da nota deve estar entre 0 e 10.
Além disso, a classe Student possui um construtor vazio e um construtor que recebe o nome e a nota do aluno. Também possui métodos getters e setters para acessar e definir os valores dos campos.
Em resumo, a classe Student é uma entidade que é mapeada para uma tabela no banco de dados usando o Java Persistence API (JPA). Os campos da entidade são mapeados para colunas na tabela e as anotações são usadas para definir as restrições de validação e outras propriedades da entidade.
¶ Mapper
O uso de um Mapper é importante em aplicações Java Spring Boot porque ele fornece uma maneira de converter objetos de um tipo para outro, permitindo que a aplicação trabalhe com diferentes representações de um mesmo conceito, de forma transparente e eficiente.
O Mapper é uma ferramenta que ajuda a lidar com a conversão de objetos em diferentes camadas da aplicação, como DTOs (objetos de transferência de dados), entidades e objetos de domínio. Ele pode ajudar a simplificar o código da aplicação, pois evita que muitas linhas de código sejam escritas para realizar conversões manuais.
Ao usar um Mapper, a lógica de conversão é isolada em uma classe específica, o que ajuda a manter o código mais organizado e legível. Além disso, a utilização de um Mapper ajuda a evitar que código de infraestrutura (como anotações JPA) seja misturado com a lógica de negócios da aplicação.
Outra vantagem do Mapper é que ele pode ajudar a melhorar o desempenho da aplicação, já que a conversão de objetos pode ser uma operação custosa em termos de processamento. O Mapper pode ser configurado para realizar as conversões de forma mais eficiente, reduzindo a sobrecarga de processamento.
O uso de Mappers também é extremamente importante por questões de segurança. É através de seu uso que as clases que evitamos com que as classes anotadas com @Entity sejam diretamente expostas nos Controllers. Dessa forma, os DTOs que são externalizado nas interfaces REST contêm somente as informações necessárias à operação especificada pelo contrato, sem expor dados potencialmente inseguros da entidade em questão.
Suponha que estamos criando uma aplicação para gerenciar informações de alunos em uma escola. Aqui está um exemplo de como um Mapper pode ser implementado para converter um objeto Student em um objeto StudentDTO:
@Mapper(componentModel = "spring")
public interface StudentMapper {
StudentMapper INSTANCE = Mappers.getMapper(StudentMapper.class);
@Mapping(target = "id", source = "student.id")
@Mapping(target = "name", source = "student.name")
@Mapping(target = "grade", source = "student.grade")
StudentDTO toDTO(Student student);
}
Nesse exemplo, a interface StudentMapper é anotada com a anotação @Mapper fornecida pela biblioteca MapStruct. Essa anotação indica que a interface é um Mapper que deve ser processado pelo MapStruct.
O método toDTO na interface StudentMapper converte um objeto Student em um objeto StudentDTO. Ele usa a anotação @Mapping para especificar como cada campo deve ser mapeado. Por exemplo, o campo id em StudentDTO é mapeado do campo id em Student.
Além disso, a interface StudentMapper também define uma constante INSTANCE que é usada para obter uma instância do Mapper em outras partes da aplicação.
Para usar o Mapper em outras partes da aplicação, basta injetar a instância do Mapper usando a anotação @Autowired. Por exemplo, aqui está como o Mapper pode ser usado em um Controller:
@RestController
@RequestMapping("/students")
public class StudentController {
@Autowired
private StudentMapper studentMapper;
@Autowired
private StudentService studentService;
@GetMapping("/{id}")
public StudentDTO getStudentById(@PathVariable Long id) {
Student student = studentService.getStudentById(id);
return studentMapper.toDTO(student);
}
// outros métodos do Controller
}
Nesse exemplo, o método getStudentById usa o Mapper para converter um objeto Student retornado pelo serviço em um objeto StudentDTO. O objeto StudentService é injetado usando a anotação @Autowired.
¶ Paginação
Será utilizada a técnica de paginação sob demanda com o uso dos recursos de banco de dados e do Spring Data JPA. Basicamente, os repositórios deverão disponibilizar métodos que retornem uma instância de Page e recebam em seus parâmetros um objeto do tipo Pageable. O Spring Data JPA calculará automaticamente a quantidade total de objetos.
Todas as respostas devem ser paginadas, salvo situações de exceção.
¶ Gerência de dependências
Gerenciamento de dependências é uma prática essencial em qualquer sistema de software e ajuda a garantir que as bibliotecas presentes nos diversos módulos da aplicação são compatríveis entre si. Ela permite que a aplicação possa incluir bibliotecas e dependências de terceiros e gerenciá-las de forma centralizada.
Existem várias ferramentas disponíveis para gerenciamento de dependências em Java Spring Boot, como o Maven e o Gradle. Essas ferramentas permitem que a aplicação especifique as dependências necessárias em um arquivo de configuração e baixe automaticamente as bibliotecas e dependências correspondentes.
Por exemplo, o arquivo pom.xml em um projeto Java Spring Boot gerenciado pelo Maven pode conter uma seção que lista as bibliotecas e dependências necessárias para a aplicação:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>4.0.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>3.1.1</version>
</dependency>
<!-- outras dependências -->
</dependencies>
Nesse exemplo, a aplicação depende das bibliotecas spring-boot-starter-web e jackson-databind. O Maven irá automaticamente baixar essas bibliotecas e quaisquer outras dependências necessárias e adicioná-las ao classpath da aplicação.
Além de gerenciar as dependências, as ferramentas de gerenciamento de dependências também ajudam a manter as versões das bibliotecas e dependências atualizadas. Por exemplo, o Maven pode verificar se há novas versões das bibliotecas e dependências especificadas no arquivo pom.xml e baixar as novas versões automaticamente.
Em resumo, a gerência de dependências é uma prática essencial em aplicações Java Spring Boot que ajuda a gerenciar as bibliotecas e dependências de software usadas na aplicação. As ferramentas de gerenciamento de dependências, como o Maven e o Gradle, permitem que a aplicação especifique as dependências necessárias em um arquivo de configuração e baixe automaticamente as bibliotecas e dependências correspondentes. Isso ajuda a simplificar o processo de desenvolvimento, garantir a compatibilidade das bibliotecas e dependências, e manter as versões atualizadas.
¶ Swagger
O Swagger é uma ferramenta que ajuda a documentar e testar APIs em aplicações Java Spring Boot. Ele fornece uma interface gráfica que permite visualizar e testar as diferentes rotas (endpoints) de uma API, bem como a documentação associada a cada rota.
Ao usar o Swagger em uma Controller, é possível gerar automaticamente a documentação da API com base nas anotações e definições da Controller. Isso ajuda a manter a documentação da API atualizada, evitando a necessidade de atualizar a documentação manualmente toda vez que a Controller é modificada.
A seguir, apresentamos algumas das vantagens de usar o Swagger em uma Controller:
-
Documentação da API mais clara e precisa: O Swagger gera automaticamente a documentação da API a partir das anotações e definições da Controller. Isso garante que a documentação esteja sempre atualizada e seja clara e precisa.
-
Facilita o teste da API: O Swagger fornece uma interface gráfica que permite testar a API sem a necessidade de escrever código. Isso facilita o processo de testar a API e garante que a API esteja funcionando corretamente.
-
Melhora a experiência do desenvolvedor: A documentação gerada pelo Swagger pode ajudar outros desenvolvedores a entenderem como usar a API e a identificar os parâmetros necessários para cada rota. Isso ajuda a melhorar a experiência do desenvolvedor e reduz o tempo necessário para desenvolver novos recursos.
-
Ajuda a padronizar a API: O Swagger fornece uma estrutura padrão para a documentação da API, o que ajuda a garantir que a documentação seja consistente e fácil de seguir. Isso pode ajudar a reduzir a curva de aprendizado para outros desenvolvedores que estão trabalhando na API.
Suponha que estamos criando uma aplicação para gerenciar informações de alunos em uma escola. Aqui está um exemplo de um método de Controller que é anotado com @ApiOperation e @ApiResponses para especificar a documentação da API:
@RestController
@RequestMapping("/api/students")
@Api(tags = "Student API", value = "Endpoints para gerenciar informações de alunos")
public class StudentController {
@Autowired
private StudentService studentService;
@PostMapping
@ApiOperation(value = "Adicionar um novo aluno", notes = "Adiciona um novo aluno ao banco de dados")
@ApiResponses(value = {
@ApiResponse(code = 201, message = "Aluno adicionado com sucesso"),
@ApiResponse(code = 400, message = "Solicitação inválida")
})
public ResponseEntity<Void> addStudent(@RequestBody StudentDTO studentDTO) {
studentService.addStudent(studentDTO);
return ResponseEntity.status(HttpStatus.CREATED).build();
}
// outros métodos do Controller
}
Nesse exemplo, o método addStudent adiciona um novo aluno ao banco de dados. Ele é anotado com @ApiOperation e @ApiResponses para especificar a documentação da API.
A anotação @ApiOperation é usada para especificar o valor, as notas e outras informações da API para a rota. A anotação @ApiResponses é usada para especificar as respostas possíveis da API para a rota.
O Controller é anotado com @Api para especificar o valor e as tags da API.
Ao executar a aplicação, é possível acessar a interface do Swagger. A partir daí, você pode visualizar a documentação da API e testar as diferentes rotas.
¶ Security
A segurança é um componente crítico em qualquer aplicação backend. O Spring Security é um framework de segurança amplamente utilizado que fornece recursos para autenticação e autorização de usuários. O Spring Security permite a integração com vários protocolos de autenticação, como OAuth e LDAP.
¶ Logging
A geração de logs é uma parte crítica de qualquer aplicação backend. Os logs permitem que os desenvolvedores monitorem o desempenho e a atividade da aplicação e identifiquem problemas. O Spring Boot fornece um sistema de logging padrão e facilmente configurável que pode ser integrado com vários sistemas de gerenciamento de logs.
¶ Opcionais
¶ Auditoria Envers
O Envers é um módulo que faz parte do projeto Hibernate ORM (Mapeamento objeto relacional), e ele provê uma maneira fácil de fazer auditoria e versionamento de suas classes entidades.
Adicionando sua dependência no pom.xml:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-envers</artifactId>
<version>4.0.4</version>
</dependency>
Implementando na inicialização do Spring Boot:
@SpringBootApplication
@EntityScan("com.example")
@EnableEnversRepositories
@EnableTransactionManagement
public class Application {
@PostConstruct
void started() {
TimeZone.setDefault(TimeZone.getTimeZone("America/Sao_Paulo"));
}
public static void main(String[] args) {
TimeZone.setDefault(TimeZone.getTimeZone("America/Sao_Paulo"));
SpringApplication.run(Application.class, args);
}
}
Implementando o Envers nas entidades:
@Audited
@Entity
@Table
@AuditTable(value = "music_audit")
@Data
public class Music implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column
private Long id;
@Column(nullable = false)
private String title;
@Column(name = "time_duration", nullable = false)
private Double timeDuration;
@ManyToOne(cascade = CascadeType.PERSIST)
@JoinColumn(name = "album_id", nullable = false)
@RestResource(exported = false)
private Album album;
}
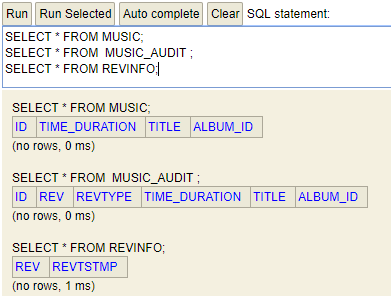
Dessa forma, três tabelas serão criadas no banco de dados: *‘music’*, *‘music_audit’* e *‘revinfo’*. A *‘revinfo’* é para versionar todas as alterações que as tabelas auditadas sofrem, e o que muda de fato fica registrado na tabela *‘music_audit’*. Conforme imagem abaixo:
¶ Convenções
¶ Convenção de nomenclatura
É importante seguir uma convenção de nomenclatura consistente para as classes, métodos e variáveis. Por exemplo, nomes de classes devem começar com uma letra maiúscula e seguir a convenção de nomes compostos como camelCase. Os nomes dos métodos e variáveis devem seguir a convenção de nomes em minúsculas e nomes compostos separados por underscore.
¶ Organização de pacotes
Os pacotes devem ser organizados de forma lógica e consistente. Por exemplo, as classes que pertencem a um determinado módulo ou funcionalidade devem ser agrupadas em um pacote comum. É importante evitar a criação de pacotes com nomes genéricos como "util" ou "misc".
¶ Uso de anotações
As anotações são usadas extensivamente em Java Spring Boot para definir a configuração da aplicação e mapear as classes e métodos. É importante usar as anotações apropriadas de forma consistente e clara.
¶ Convenção de nomenclatura de métodos HTTP
Os métodos HTTP devem ser nomeados de acordo com a ação que eles executam. Por exemplo, o método POST deve ser usado para criar um novo recurso, o método PUT deve ser usado para atualizar um recurso existente e o método DELETE deve ser usado para excluir um recurso.
¶ Documentação
A documentação é importante para manter a clareza e a consistência em todo o código. É importante documentar as classes, métodos e variáveis com comentários claros e concisos. Além disso, a documentação da API deve ser fornecida com a ajuda de ferramentas como o Swagger.
¶ Padrões
¶ Repository
O padrão Repository é usado para abstrair a camada de persistência de dados em uma aplicação. Ele define uma interface comum para acessar os dados e pode ser usado para interagir com diferentes bancos de dados e tecnologias de armazenamento de dados. O padrão Repository ajuda a manter o código mais modular e desacoplado, permitindo que as diferentes camadas da aplicação sejam modificadas independentemente umas das outras.
¶ Injeção de Dependência
A Injeção de Dependência é um padrão que ajuda a separar as responsabilidades das diferentes classes em uma aplicação. Ele permite que as dependências sejam gerenciadas por um contêiner de injeção de dependência, em vez de serem criadas manualmente em cada classe. Isso ajuda a tornar o código mais modular e facilita a manutenção, uma vez que as dependências podem ser atualizadas em um local centralizado.
¶ DTO (Data Transfer Object)
O padrão DTO é usado para transferir dados entre as diferentes camadas de uma aplicação. Ele define um objeto que representa os dados necessários para uma operação e pode ser usado para minimizar o tráfego de rede e reduzir a quantidade de dados transmitidos. O padrão DTO ajuda a manter o código mais modular e desacoplado, permitindo que as diferentes camadas da aplicação sejam modificadas independentemente umas das outras.
¶ Microserviços
O padrão de microserviços é uma arquitetura que divide uma aplicação em serviços menores e independentes. Cada serviço é responsável por uma única funcionalidade e pode ser implantado e escalado independentemente dos outros serviços. O uso de microserviços pode ajudar a tornar a aplicação mais modular, escalável e fácil de manter.
¶ Service
O padrão Service é usado para separar a lógica de negócios em uma camada separada, permitindo que a camada de controle (Controller) seja responsável apenas por lidar com as solicitações HTTP e chamar os serviços apropriados. O uso do padrão Service ajuda a manter o código mais modular, desacoplado e fácil de testar, permitindo que a lógica de negócios seja escrita em uma camada separada.
¶ Mapper
O padrão Mapper é usado para converter objetos de uma camada para outra. Isso é especialmente útil quando se trabalha com DTOs e entidades, que podem ter campos diferentes. O Mapper ajuda a manter o código mais modular, desacoplado e fácil de testar, permitindo que a conversão de objetos seja feita em uma camada separada.
¶ Gerência de Dependências
A Gerência de Dependências é a prática de gerenciar as dependências da aplicação, garantindo que as versões corretas das bibliotecas e dependências estejam sendo usadas. O uso do Maven, uma ferramenta de gerenciamento de dependências amplamente utilizada na comunidade Java, é obrigatório para garantir que as dependências da aplicação sejam gerenciadas de forma eficiente e padronizada.
¶ Swagger
O Swagger é uma ferramenta de documentação de API que permite documentar e testar APIs de forma clara e consistente. O uso do Swagger em aplicações Java Spring Boot ajuda a manter a documentação atualizada, melhorar a experiência do desenvolvedor e padronizar a API. A forma como a documentação do Swagger é gerada nas versões 3.0+ do Spring mudou, objetivando que o suporte à OpenAPI Spec 3+ fosse consolidado. As dependências necessárias para que essa documentação ainda continue sendo mantida são mostradas a seguir.
¶ Status HTTP
Os resultados serão retornados em objetos padrão (envelopes) no formato definido pelo Datasus, devendo possuir o código de status HTTP apropriado, conforme a seguinte lista:
200 OK
Resposta padrão para solicitações HTTP bem-sucedidas. A resposta real dependerá do método de solicitação usado. Em uma solicitação GET, a resposta conterá uma entidade correspondente ao recurso solicitado. Em uma solicitação POST, a resposta conterá uma entidade descrevendo ou contendo o resultado da ação.201 Created
A solicitação foi atendida, resultando na criação de um novo recurso.202 Accepted
A solicitação foi aceita para processamento, mas o processamento não foi concluído. A solicitação pode ou não ser eventualmente atendida e pode ser desaprovada quando o processamento ocorre.400 Bad Request
O servidor não pode processar a solicitação devido a um aparente erro do cliente (por exemplo, sintaxe de solicitação malformada, tamanho muito grande, enquadramento de mensagem de solicitação inválido ou roteamento de solicitação enganoso).401 Unauthorized
Semelhante ao 403 Forbidden, mas especificamente para uso quando a autenticação é necessária e falhou ou ainda não foi fornecida. A resposta deve incluir um campo de cabeçalho WWW-Authenticate contendo um desafio aplicável ao recurso solicitado. Consulte Autenticação de acesso básico e Autenticação de acesso Digest . 401 significa semanticamente "não autorizado", o usuário não possui credenciais de autenticação válidas para o recurso de destino.403 Forbidden
A solicitação continha dados válidos e foi compreendida pelo servidor, mas o servidor está recusando a ação. Isso pode ocorrer porque o usuário não tem as permissões necessárias para um recurso ou precisa de uma conta de algum tipo, ou tenta uma ação proibida (por exemplo, criar um registro duplicado onde apenas um é permitido). Esse código também é normalmente usado se a solicitação forneceu autenticação respondendo ao desafio do campo de cabeçalho WWW-Authenticate, mas o servidor não aceitou essa autenticação. A solicitação não deve ser repetida.404 Not Found
O recurso solicitado não foi encontrado, mas pode estar disponível no futuro. Solicitações subsequentes do cliente são permitidas.
¶ Bibliotecas
- @spring-boot-starter-web
- @spring-boot-starter-data-jpa
- @spring-boot-starter-security
- @spring-boot-starter-oauth2-client
- @spring-security-oauth2
- @mapstruct
¶ Bibliotecas internas
Para utilizar as bibliotecas proprietárias do DATASUS deverá ser utilizado o settings.xml do Maven:
https://nexus.saude.gov.br/repository/raw-hosted/maven/settings.xml
Esse arquivo de configuração do Gerenciador de Empacotamento possui acesso a todos os Repositórios de Pacotes do DATASUS, novos e legados. O download destes pacotes internos só serão possíveis através do uso do profile "saude" no Maven e com acesso à rede interna, via VPN.
Esse arquivo de configuração do Gerenciador de Empacotamento Maven possui acesso a todos os Repositórios de Pacotes do Datasus, novos e legados.
¶ Bibliotecas - DATASUS/COATIC
- @coatic-springframework-core
Biblioteca responsável por autenticar e gerar os Tokens de acesso aos serviços da arquitetura com base nas permissões de cada aplicação. É integrada ao serviço de autorização do Datasus.
A versão mais atualizada do template de código que utiliza essa e outras bibliotecas internas do DATASUS pode ser encontrada em:
https://gitlab.saude.gov.br/datasus/arquitetura/coatic/spring-boot-template
¶ Procedimentos para utilização
-
Configure a IDE com a versão Java indicada nesta página.
-
Espere baixar todas as dependências base anotadas no pom.xml do projeto. Ao finalizar o download das bibliotecas, o desenvolvedor poderá subir a aplicação base usando o comando
mvn clean install -P saude(para limpar e instalar o projeto) e, em seguida, o comandomvn spring-boot:run(para subir a aplicação).
Mais informações de como fazer realizar o deploy da aplicação podem ser encontradas em: https://wiki-coatic.saude.gov.br/pt-br/devsecops#template-de-esteira-de-automação
¶ Guia de atualização do Spring Boot
Esse guia é disponibilizado com o intuito de auxiliar na atualização de versões das principais bibliotecas utilizadas nos componentes internos do Datasus desenvolvidos em Java que utilizam o framework Spring Boot. Essa atualização é de suma importância, pois há também requisitos relacionados a atualização do SDK Java. Mais específicamente o Spring Boot 4.x requer, ao menos, o SKD Java 17. Entretanto, no intuito de garantir a maior longevidade, manutenabilidade e segurança desses componentes, é fortemente recomendado que a atualização seja feita também para o Java SDK versão 25, que é atualmente a versão LTS (Long-Term-Support).
Outro fator de suma importância diz respeito ao Spring Security. Dentre todas as bibliotecas que compõem o framework Spring Boot, o maior conjunto de breaking changes se concentra nas bibliotecas que tratam de gerenciamento de acesso e segurança, empacotadas sob o nome de Spring Security. Isso é especialmente importante no contexto Datasus pois vários componentes internos utilizam largamente esse conjunto de bibliotecas, sobretudo as funcionalidades relacionadas a autenticação e autorização.
Este guia é focado em auxiliar na migração de componentes que utilizam a versão 2.x do Spring Boot. Versões anteriores estão fora do escopo. Informações para migração de componentes que utilizam versões menos que a 2.x podem ser encontradas em https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-2.0-Migration-Guide.
¶ Etapas de Migração
A migração para o Spring Boot versão 4.x deve ser feita preferencialmente em duas etapas:
- Migração para o Spring Boot 3.x;
- Migração para o Spring Boot 4.x;
- Migração para o Spring Security 6.x;
- Migração para o Spring Security 7.x;
Essa divisão em etapas é importante pois ajuda a diminuir conflitos de versões e facilita o gerenciamento de dependências (sobretudo as transitivas) ao longo do processo de migração.
¶ Migração para o Spring Boot 2.7.x
Consultar:
- https://docs.spring.io/spring-boot/docs/2.7.x/reference/html/dependency-versions.html#appendix.dependency-versions
- https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-Config-Data-Migration-Guide
¶ Migração para o Spring Boot 3.x
Consultar:
- https://docs.spring.io/spring-boot/docs/3.0.x/reference/html/dependency-versions.html#appendix.dependency-versions
- https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-3.0-Migration-Guide
¶ Migração para o Spring Boot 4.x
Consultar:
- https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-4.0-Release-Notes
- https://github.com/spring-projects/spring-boot/wiki/Spring-Boot-4.0-Migration-Guide
¶ Migração para o Spring Security 6.0
Consultar:
¶ Migração para o Spring Security 7.0
Consultar:
¶ Quarkus
¶ Introdução
O Quarkus é um framework Java nativo para Kubernetes, projetado para funcionar com GraalVM e HotSpot, tornando o Java uma plataforma de destaque para implementações serverless, microsserviços e ambientes em nuvem. Conhecido pelo slogan "Supersonic Subatomic Java", o Quarkus proporciona tempo de inicialização extremamente rápido e baixo consumo de memória.
O Quarkus é uma alternativa ao Spring Boot especialmente indicada para cenários que exigem:
- Tempo de inicialização sub-segundo (escalabilidade horizontal rápida, serverless)
- Compilação nativa via GraalVM (binários executáveis sem JVM)
- Alta eficiência de memória em containers e Kubernetes
Assim como o Spring Boot, o Quarkus suporta injeção de dependência (via CDI/ArC), acesso a banco de dados (via Hibernate ORM com Panache), APIs REST (via RESTEasy Reactive / Jakarta REST), segurança (via OIDC e SmallRye JWT), entre outros.
¶ Comparativo com Spring Boot
| Característica | Spring Boot | Quarkus |
|---|---|---|
| Injeção de Dependência | Spring IoC (@Autowired, @Component) |
CDI/ArC (@Inject, @ApplicationScoped) |
| REST API | Spring MVC / WebFlux | RESTEasy Reactive (JAX-RS) |
| ORM / Persistência | Spring Data JPA | Hibernate ORM com Panache |
| Segurança | Spring Security | Quarkus OIDC / SmallRye JWT |
| Configuração | application.yml / application.properties |
application.properties |
| Build tool | Maven / Gradle | Maven / Gradle |
| Compilação Nativa | Spring Native | GraalVM Native Image (nativo) |
| Dev Experience | Spring DevTools | Quarkus Dev Mode (hot reload automático) |
| Documentação de API | Springdoc / Swagger | SmallRye OpenAPI / Swagger UI |
¶ Versão Mínima
O Quarkus 3.x requer Java 17 ou superior. Para novos projetos, recomenda-se Java 21 (LTS) ou Java 25.
¶ Arquitetura
A arquitetura de uma aplicação Quarkus segue as mesmas camadas descritas anteriormente (Segurança, Serviço, API e Aplicação), porém utilizando especificações Jakarta EE e MicroProfile em vez das abstrações do Spring:
- RESTEasy Reactive no lugar do Spring MVC para exposição de APIs REST
- CDI (Contexts and Dependency Injection) no lugar do Spring IoC para injeção de dependências
- Hibernate ORM com Panache no lugar do Spring Data JPA para acesso a dados
- SmallRye OpenAPI no lugar do Springdoc para documentação de API
- Quarkus OIDC no lugar do Spring Security OAuth2 para autenticação
¶ Estrutura de diretórios
├── src
│ ├── main
│ │ ├── java
│ │ │ └── com
│ │ │ └── example
│ │ │ ├── config
│ │ │ │ └── SecurityConfig.java
│ │ │ ├── infrastructure
│ │ │ │ └── LoggingFilter.java
│ │ │ ├── resource
│ │ │ │ ├── dto/
│ │ │ │ ├── mapper/
│ │ │ │ └── StudentResource.java
│ │ │ ├── service
│ │ │ │ └── StudentService.java
│ │ │ └── domain
│ │ │ ├── entity
│ │ │ │ └── Student.java
│ │ │ └── repository
│ │ │ └── StudentRepository.java
│ │ └── resources
│ │ ├── application.properties
│ │ └── META-INF
│ │ └── resources
│ │ └── index.html
│ └── test
│ ├── java
│ └── resources
└── pom.xml
No Quarkus, o equivalente ao Controller do Spring MVC é chamado de Resource, seguindo a nomenclatura do Jakarta REST (JAX-RS).
¶ Componentes de Referência
¶ Resource (API)
O Resource é o equivalente ao Controller no Spring Boot. Utiliza anotações JAX-RS para mapear rotas HTTP. Os Resources devem expor sempre interfaces REST. Casos omissos devem ser analisados individualmente.
@Path("/api/students")
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
public class StudentResource {
@Inject
StudentService studentService;
@Inject
StudentMapper studentMapper;
@GET
@Path("/{id}")
public Response getStudentById(@PathParam("id") Long id) {
Student student = studentService.getStudentById(id);
if (student == null) {
return Response.status(Response.Status.NOT_FOUND).build();
}
return Response.ok(studentMapper.toDTO(student)).build();
}
@POST
public Response createStudent(StudentDTO studentDTO) {
Student student = studentService.createStudent(studentDTO.toStudent());
return Response.created(URI.create("/api/students/" + student.id))
.entity(studentMapper.toDTO(student))
.build();
}
@PUT
@Path("/{id}")
public Response updateStudent(@PathParam("id") Long id, StudentDTO studentDTO) {
Student updated = studentService.updateStudent(id, studentDTO);
if (updated == null) {
return Response.status(Response.Status.NOT_FOUND).build();
}
return Response.ok(studentMapper.toDTO(updated)).build();
}
@DELETE
@Path("/{id}")
public Response deleteStudent(@PathParam("id") Long id) {
boolean deleted = studentService.deleteStudent(id);
if (!deleted) {
return Response.status(Response.Status.NOT_FOUND).build();
}
return Response.noContent().build();
}
}
¶ Service
O Service no Quarkus utiliza CDI para injeção de dependência. O escopo padrão recomendado é @ApplicationScoped. A anotação @Transactional funciona da mesma forma que no Spring Boot.
@ApplicationScoped
public class StudentService {
@Inject
StudentRepository studentRepository;
public Student getStudentById(Long id) {
return studentRepository.findById(id);
}
@Transactional
public Student createStudent(Student student) {
studentRepository.persist(student);
return student;
}
@Transactional
public Student updateStudent(Long id, StudentDTO studentDTO) {
Student student = studentRepository.findById(id);
if (student == null) return null;
student.name = studentDTO.getName();
student.grade = studentDTO.getGrade();
return student;
}
@Transactional
public boolean deleteStudent(Long id) {
return studentRepository.deleteById(id);
}
}
¶ Repository (Panache)
O Quarkus oferece duas abordagens para persistência com Panache:
1. Padrão Repository (equivalente ao Spring Data — preferido por manter separação de responsabilidades):
@ApplicationScoped
public class StudentRepository implements PanacheRepository<Student> {
public List<Student> findByGrade(int grade) {
return list("grade", grade);
}
public Page<Student> findAll(int pageIndex, int pageSize) {
return findAll().page(pageIndex, pageSize);
}
}
2. Active Record (entidade autogerenciada — alternativa mais concisa):
@Entity
@Table(name = "TB_STUDENT", schema = "DBSIS")
public class Student extends PanacheEntity {
@NotBlank
public String name;
@Min(0) @Max(10)
public int grade;
public static List<Student> findByGrade(int grade) {
return list("grade", grade);
}
}
No padrão Active Record, os métodos de acesso a dados ficam na própria entidade, eliminando a necessidade de um Repository separado. Para novos projetos, o padrão Repository é preferido por manter a separação de responsabilidades e facilitar testes.
¶ Entity
No Quarkus com Panache e padrão Repository, a entidade permanece como POJO anotado com JPA. Uma diferença em relação ao Spring Boot é que os campos públicos são aceitos — o Panache gera acessores automaticamente em tempo de compilação:
@Entity
@Table(name = "TB_STUDENT", schema = "DBSIS")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
public Long id;
@NotBlank
@Column(nullable = false)
public String name;
@Min(0)
@Max(10)
@Column(nullable = false)
public int grade;
}
¶ Mapper
O uso de MapStruct é idêntico ao Spring Boot, com a diferença no componentModel: usar "jakarta-cdi" em vez de "spring".
@Mapper(componentModel = "jakarta-cdi")
public interface StudentMapper {
@Mapping(target = "id", source = "student.id")
@Mapping(target = "name", source = "student.name")
@Mapping(target = "grade", source = "student.grade")
StudentDTO toDTO(Student student);
}
¶ Configuração
O Quarkus utiliza application.properties para configuração. Suporta perfis via prefixo %perfil.:
# Datasource
quarkus.datasource.db-kind=postgresql
quarkus.datasource.username=${DB_USER:postgres}
quarkus.datasource.password=${DB_PASS:postgres}
quarkus.datasource.jdbc.url=jdbc:postgresql://localhost:5432/mydb
# Hibernate ORM
quarkus.hibernate-orm.database.generation=validate
quarkus.hibernate-orm.log.sql=false
# HTTP
quarkus.http.port=8080
# OIDC (autenticação)
quarkus.oidc.auth-server-url=${OIDC_URL}
quarkus.oidc.client-id=${OIDC_CLIENT_ID}
# Perfil de desenvolvimento (sobrescreve configurações acima)
%dev.quarkus.hibernate-orm.database.generation=drop-and-create
%dev.quarkus.hibernate-orm.log.sql=true
# Perfil de teste
%test.quarkus.datasource.db-kind=h2
%test.quarkus.datasource.jdbc.url=jdbc:h2:mem:test
¶ Paginação
A paginação no Quarkus com Panache é feita via Page e PanacheQuery:
@ApplicationScoped
public class StudentRepository implements PanacheRepository<Student> {
public List<Student> findByGradePaged(int grade, int pageIndex, int pageSize) {
return find("grade", grade)
.page(pageIndex, pageSize)
.list();
}
}
Todas as respostas devem ser paginadas, salvo situações de exceção — mesma convenção do Spring Boot.
¶ Compilação Nativa
Uma das principais vantagens do Quarkus é a compilação para binário nativo via GraalVM ou Mandrel, eliminando a necessidade de JVM em execução:
# Build nativo com GraalVM/Mandrel instalado localmente
./mvnw package -Pnative
# Build nativo via container (não requer GraalVM local)
./mvnw package -Pnative -Dquarkus.native.container-build=true
O binário nativo oferece:
- Tempo de inicialização de milissegundos (vs. segundos na JVM)
- Consumo de memória drasticamente reduzido
- Ideal para containers, Kubernetes e funções serverless
Para build nativo via container, o Docker ou Podman deve estar disponível no ambiente de build.
¶ Dev Mode e Dev Services
O Quarkus oferece um modo de desenvolvimento com hot reload automático, sem necessidade de reiniciar a aplicação:
./mvnw quarkus:dev
O Dev Mode inclui o Dev UI (disponível em /q/dev) com painéis para configuração, extensões instaladas e muito mais.
Os Dev Services provisionam automaticamente containers Docker para dependências externas (PostgreSQL, Kafka, Redis, etc.) durante o desenvolvimento e testes, sem configuração manual:
# Nenhuma configuração de URL necessária em modo dev!
# O Quarkus provisiona automaticamente um container PostgreSQL via Testcontainers.
quarkus.datasource.db-kind=postgresql
¶ Testes
@QuarkusTest
class StudentResourceTest {
@Test
void testGetStudentById() {
given()
.when().get("/api/students/1")
.then()
.statusCode(200)
.body("name", notNullValue());
}
}
¶ Extensões (Dependências)
O Quarkus usa extensões em vez de dependências convencionais. Cada extensão integra uma biblioteca ao runtime do Quarkus de forma otimizada para JVM e native.
Adicionar extensão via CLI:
./mvnw quarkus:add-extension -Dextensions="resteasy-reactive-jackson,hibernate-orm-panache,jdbc-postgresql"
Principais extensões:
<dependencies>
<!-- REST API -->
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-resteasy-reactive-jackson</artifactId>
</dependency>
<!-- Persistência -->
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-hibernate-orm-panache</artifactId>
</dependency>
<!-- Banco de dados -->
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jdbc-postgresql</artifactId>
</dependency>
<!-- Validação -->
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-hibernate-validator</artifactId>
</dependency>
<!-- Segurança / OIDC -->
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-oidc</artifactId>
</dependency>
<!-- OpenAPI / Swagger UI -->
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-smallrye-openapi</artifactId>
</dependency>
<!-- MapStruct (mesmo do Spring Boot) -->
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
<version>1.6.3</version>
</dependency>
<!-- Testes -->
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-junit5</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
¶ Bibliotecas internas DATASUS/COATIC
As mesmas bibliotecas internas disponíveis para Spring Boot podem ser utilizadas no Quarkus, desde que compatíveis com Jakarta EE. Consulte a COATIC para verificar a disponibilidade de extensões Quarkus equivalentes às bibliotecas proprietárias.
O template de código Quarkus do DATASUS pode ser encontrado em:
https://gitlab.saude.gov.br/datasus/arquitetura/coatic/quarkus-template
¶ Quando usar Spring Boot vs Quarkus
| Cenário | Recomendação |
|---|---|
| Projetos legados / equipes familiarizadas com Spring | Spring Boot |
| Novos microsserviços cloud-native / Kubernetes | Quarkus |
| Ambientes serverless (AWS Lambda, Azure Functions) | Quarkus (native) |
| Necessidade de compilação nativa | Quarkus |
| Ecossistema Spring maduro necessário (Batch, Integration) | Spring Boot |
| Alta densidade de containers com restrição de memória | Quarkus |
| Equipe familiarizada com Jakarta EE / MicroProfile | Quarkus |
Ambos os frameworks são suportados pelo DATASUS. A escolha deve ser feita com a COATIC no início do projeto, levando em consideração o cenário de uso, as características da equipe e os requisitos de infraestrutura.